I'm trying to get everything running smoothly on the Linux machines. I really am. And I'm close, but I'm not there yet, and I'm not sure if I'll ever get there.
Many of the apps I use on macOS are also available on Linux. This is awesome. It's the ones I love, but need to leave behind that are causing all the trouble.
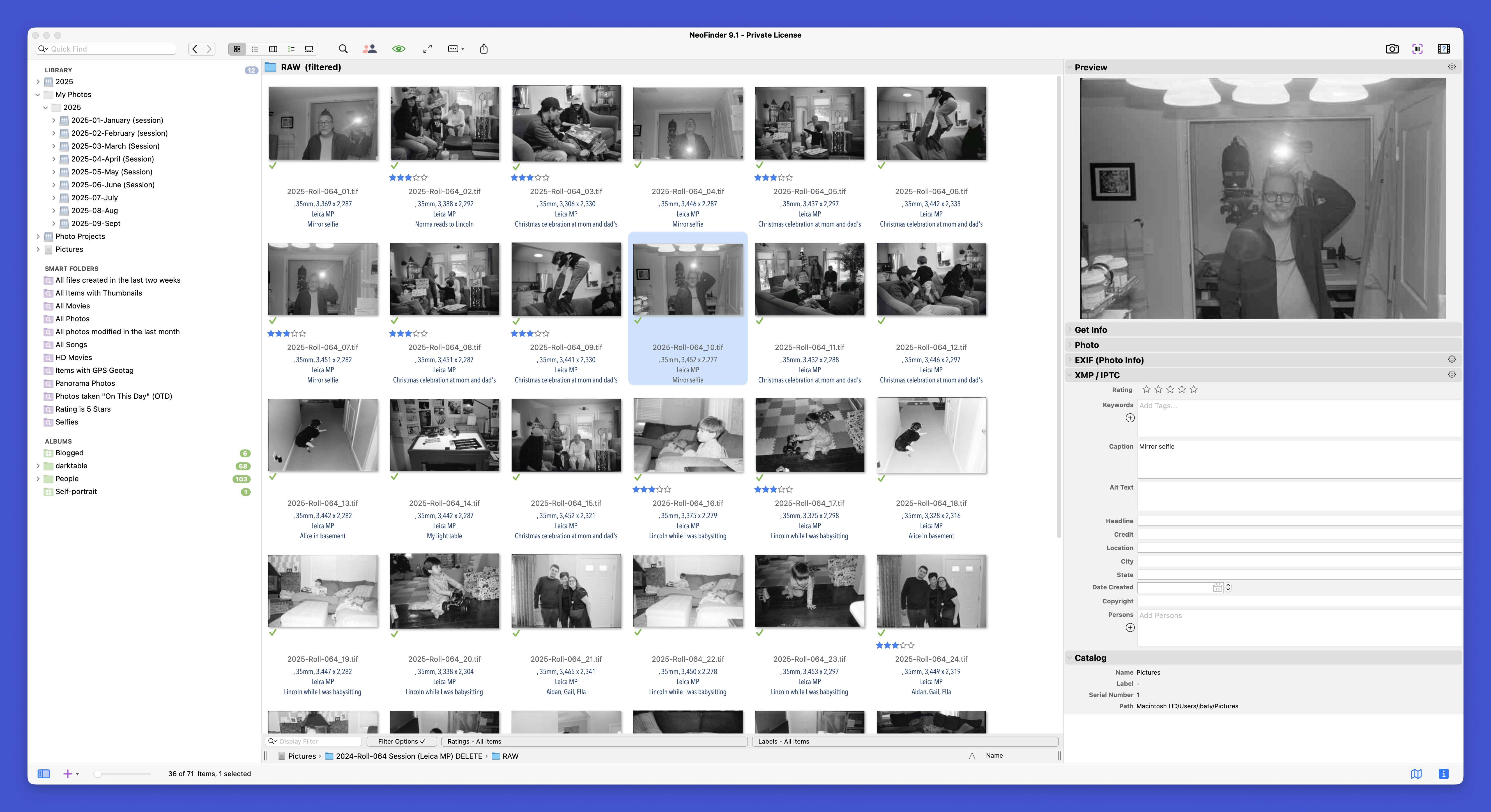
Most of the problems are around photo processing. I've spent many (many!) hours learning and testing Darktable for RAW processing. It's a powerful tool with a lot of clever ideas, some of which I actually prefer to its Mac counterparts. However, Darktable is not at all pleasant to use. Once the cleverness and new-shiny factors are past, I'm forced to live in a clumsy, awkward, unpleasant, unattractive environment. I miss Capture One dearly. Capture One gets me results I like quickly and easily. It's better.
Then there's scanning. I've spent years wrangling SilverFast to a point where I don't hate it. Recent updates have introduced the feature of scanning multiple (3, in my case) frames at once, making it much faster. I used to use Vuescan, and it's available on Linux, so I tried it. So so slow. And it does a pretty poor job with color film.
With digital camera scans, nothing beats Negative Lab Pro for doing inversions. NLP requires Lightroom Classic, so I'm kind of stuck there. I tried the Negadoctor feature of Darkroom and, while feasible, inversions are slow and tedious.
Photography is not just something I tinker with occasionally. It's my most enjoyable hobby. I don't think I want to suffer through it, just so I can use Linux.
There are several other apps that I seriously miss from macOS. BBEdit is still unbeatable for ease of use, stability, and capabilities when it comes to manipulating text. Tinderbox is one of a kind for outlining and notes. There's nothing on Linux comparable with OmniFocus for task management. And so on.
But the deal-breaking omission might be Messages. Everyone I communicate with regularly uses Apple Messages and Facetime, exclusively. I can't stand typing on my phone, so having to hear an alert, grab my phone, and fumble my way through a reply is maddening. Also, I can't quickly send people links or photos from where I am. How am I supposed to share that hilarious meme if it's so much effort?
On the other hand, I love using the Framework laptop when away from my desk. I like the keyboard better than the MacBook Air's. Knowing I can easily upgrade or fix things (inexpensively) for years is very compelling.
So all this to say that I may end up using a Mac on the desktop and Linux on the laptop. I swore I'd never do that again. Between sync, paths, configuration issues, filename case mismatches, and wildly different key bindings, using both is a royal pain in the ass.
This rambling post is just me working through all of this. I'm typing this post using BBEdit on the Mac Mini, and I gotta say that having the standard Emacs keybindings everywhere is a compelling case for macOS for me.
I'll keep you posted.